Ajax 技术与原理
Ajax 简介
ajax 的特点
- AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。
- AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
- AJAX 是与服务器交换数据并更新部分网页的艺术,在不重新加载整个页面的情况下。
Ajax 所包含的技术
ajax 并不是一种新的技术,而是几种原有技术的结合体。它由下列技术组合而成。
- 使用 CSS 和 XHTML 来表示。
- 使用 DOM 模型来交互和动态显示。
- 使用 XMLHttpRequest 来和服务器进行异步通信。
- 使用 JavaScript 来绑定和调用。
AJAX 的核心是 XMLHttpRequest 对象。
AJAX 的工作原理
AJAX 的工作原理相当于在用户和服务器之间加了—个中间层(AJAX引擎),使用户操作与服务器响应异步化。并不是所有的用户请求都提交给服务器。像—些数据验证和数据处理等都交给 Ajax 引擎自己来做,只有确定需要从服务器读取新数据时再由 Ajax 引擎代为向服务器提交请求。
传统方式
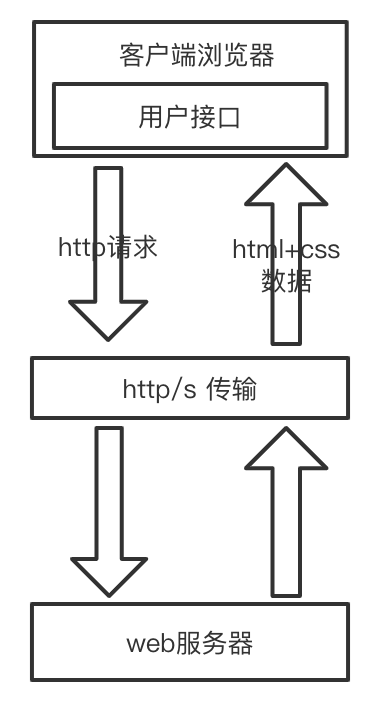
AJAX
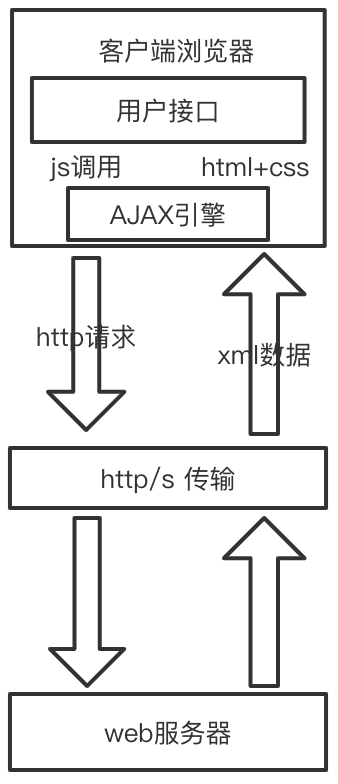
交互方式
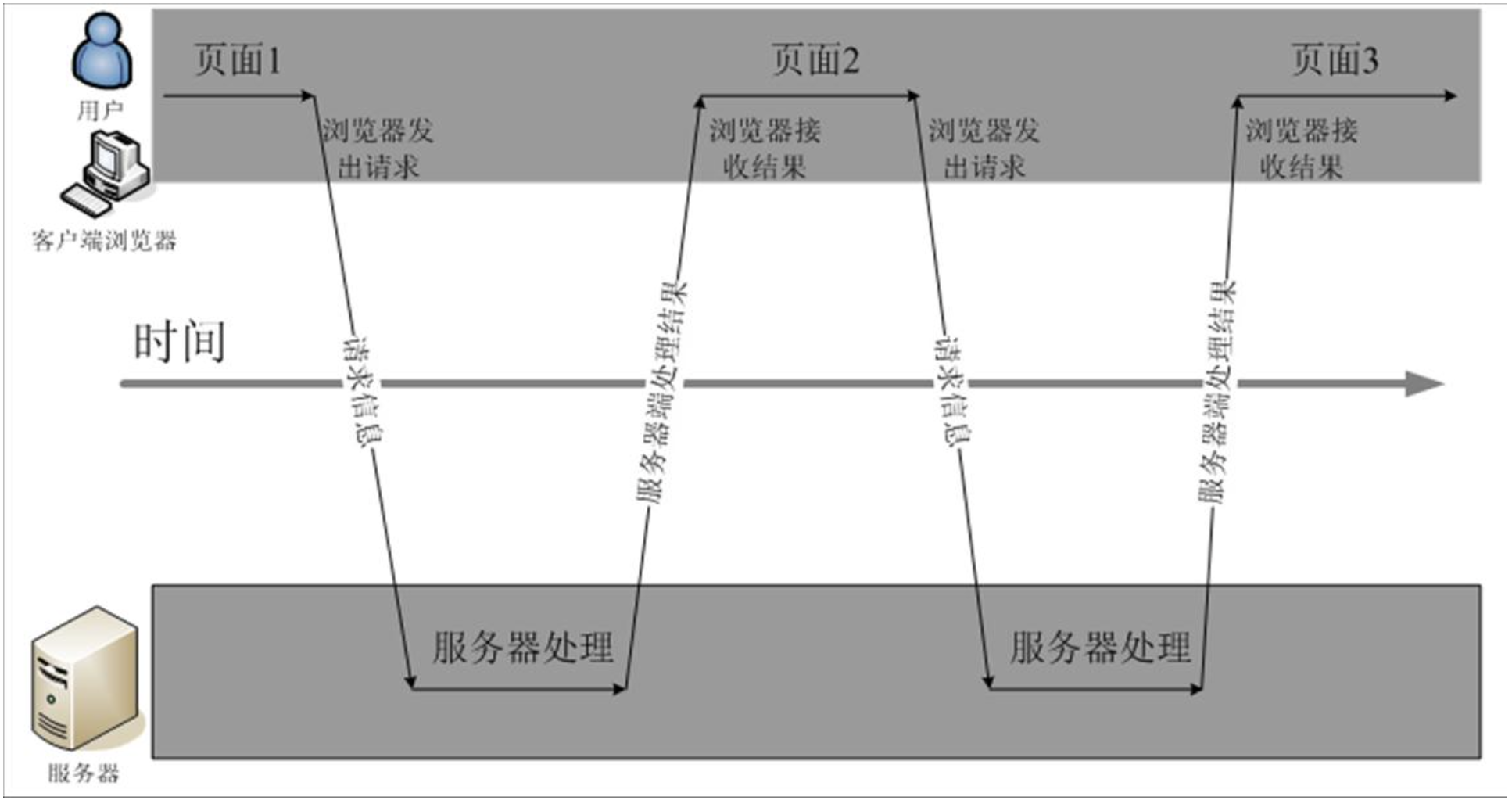
浏览器的普通交互方式
浏览器的 Ajax 交互方式
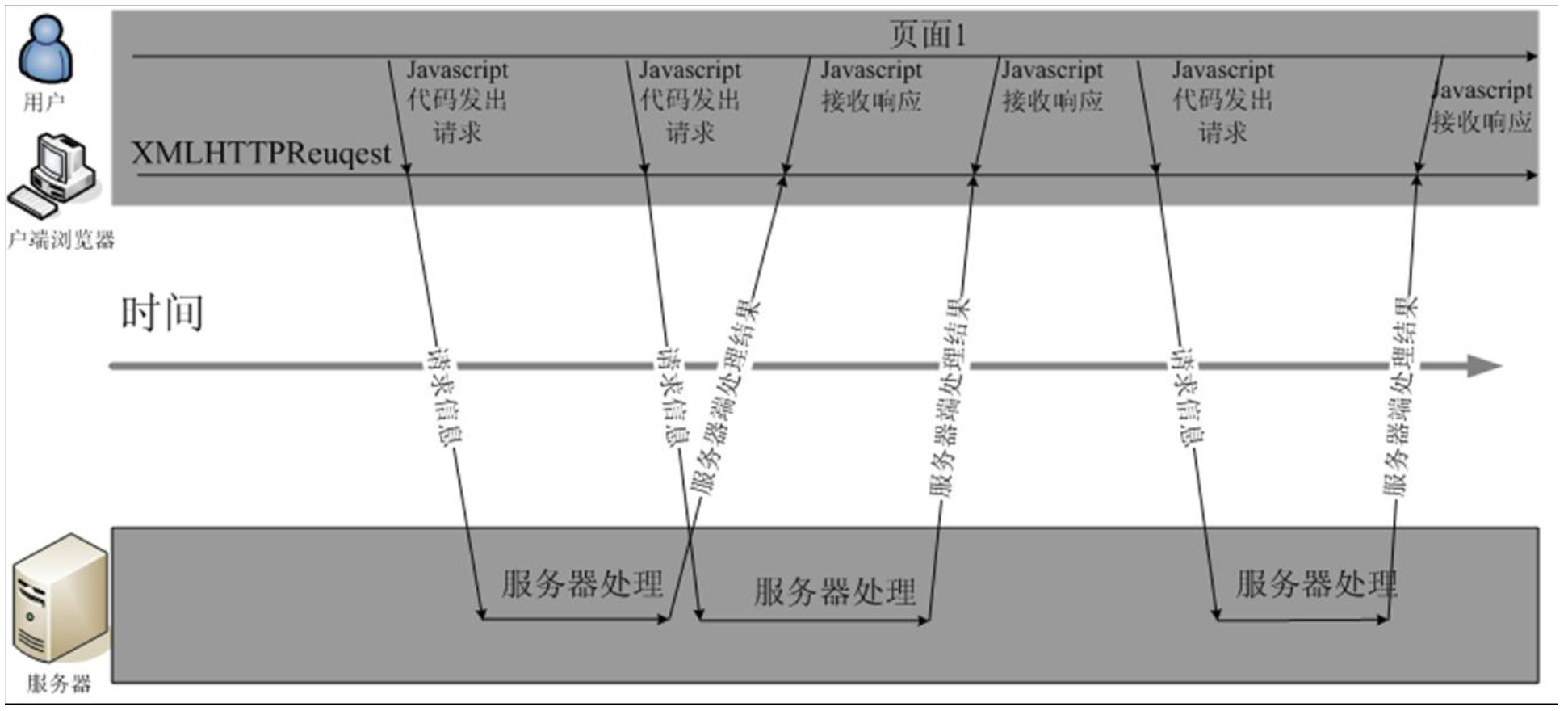
可以从上图看出,通过 AJAX 的方式进行交互可以不需要等到页面上一步操作完毕即可做新的动作。局部刷新页面即可。AJAX 提升了用户体验。
优点与缺点
优点:
- 页面无刷新更新,用户的体验非常好;
- 异步通信,响应更快
- 可以将一些服务器工作转移到客户端,利用客户端资源来处理,减轻服务器和带宽的压力,节约空间和带宽租用成本;
- Ajax 可使因特网应用程序更小、更快、更友好。
缺点:
- Ajax 不支持浏览器 back 返回按钮;
- 有安全问题,Ajax 暴露了与服务器交互的细节;(安全)
- 对搜索引擎不友好;
AJAX核心
Ajax 技术的核心是 XMLHttpRequest 类,简称 XHR,它允许脚本异步调用 HTTP API。浏览器在 XMLHttpRequest 类上定义了 HTTP API,这个类的每个实例都表示一个 独立 的 请求/响应对象,并且这个实例对象上的属性和方法允许指定细节和提取响应数据。
创建XHR对象
var xhr = new XMLHttpRequest()open
xhr.open(method, url, async)- method: 指定 HTTP 请求的方法,不区分大小写;
- 第二个参数用于指定 HTTP 请求的 URL 地址,可以是 绝对URL 或 相对URL;
- 绝对URL:需要满足 "同源策略"(服务器明确允许跨域请求的情况除外);
- 相对URL:即相对于文档的 URL;
- async:
- 指定脚本是否以异步的方式调用此次 Ajax 请求
- 该参数默认为 true,表示异步调用此次 Ajax 请求,不阻塞后续脚本的执行
setRequestHeader
如果你的 HTTP 请求需要设置请求头,那么调用 open 方法之后的下个步骤就是设置它,使用的方法是:setRequestHeader
xhr.setRequestHeader("Content-Type", "application/x-www-form-urlencoded")
xhr.setRequestHeader(name, value)- name:请求头名称;
- value:请求头的值。
send()
var xhr = new XMLHttpRequest();
xhr.open("POST", "xxxxx");
// 把 msg 作为请求主体发送
xhr.send(msg);- POST 请求通常都拥有请求主体,可在 send 方法中指定它;
- POST 请求的请求主体,应该匹配
setRequestHeader方法所指定的Content-Type头
获取响应
一个完整的 HTTP 响应由 状态码、响应头和 响应主体 组成,这三者都可以通过 XMLHttpRequest 对象提供的属性和方法获取。
readyState 属性是一个整数,它的值代表了不同的 HTTP 请求状态:
- 0:初始值,表示请求未初始化,
open方法尚未调用; - 1:启动请求,
open方法已经调用,但尚未调用send方法; - 2:请求发送,已经调用
send方法,但尚未接收到响应; - 3:接收响应,已经接受到部分响应数据,主要是响应头;
- 4:HTTP 响应完成,已经接收到全部响应数据,而且可以在客户端使用。
xhr.onreadystatechange = function () {
if (xhr.readyState === 4) {
console.log('响应完成')
}
};每次 readyState 属性值的改变都会触发 onreadystatechange 事件,但是只有 readyState 的值为4才是我们所关心的状态。
status
readyState的属性值只代表此时的 HTTP 请求处于哪个阶段:上述的5个阶段。 真正判断请求成功与否需要通过 HTTP 状态码 判断,它存储在 XMLhttpRequest 的 status 属性上;
- 1xx:临时响应
- 2xx:成功
- 3xx:重定向
- 4xx:请求错误
- 5xx:服务器错误
responseText
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function () {
if (xhr.readyState !== 4) return;
if (xhr.status >= 200 && xhr.status < 300 || xhr.status === 304) {
var res = JSON.parse(xhr.responseText);
oTime.innerText = res.data;
}
};
xhr.open("GET", "xxxxx");
xhr.send();getAllResponseHeaders
用于一次性返回可查询的全部响应头信息
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function () {
if (xhr.readyState !== 4) return;
if (xhr.status >= 200 && xhr.status < 300 || xhr.status === 304) {
oTime.innerText = xhr.getAllResponseHeaders();
}
};
xhr.open("GET", "xxxxx");
xhr.send();getResponseHeader
方法用于查询单一响应头信息,需要传入一个指定 "头名称" 的字符串作为参数
var xhr = new XMLHttpRequest();
xhr.onreadystatechange = function () {
if (xhr.readyState !== 4) return;
if (xhr.status >= 200 && xhr.status < 300 || xhr.status === 304) {
oTime.innerText = xhr.getResponseHeader("Content-Type");
}
};
xhr.open("GET", "xxxxx");
xhr.send();由于XMLHttpRequest会自动处理 cookie,将 cookie 从getAllResponseHeaders方法返回的响应头集合中过滤掉,并且如果给getResponseHeader方法传递 "Set-Cookie" 或 "Set-Cookie2",则返回 null。
同步响应
var xhr = new XMLHttpRequest();
// 指定 open 方法的第三个参数为 false
xhr.open("GET", "xxxxxx", false);
// send 方法的调用将阻塞后面代码的执行,直到此次 HTTP 请求完成
xhr.send();
// 不再需要监听 readystatechange 事件
if (xhr.status >= 200 && xhr.status < 300 || xhr.status === 304) {
oTime.innerText = JSON.parse(xhr.response).date;
} else {
// 如果请求不成功,就报错
throw new Error(xhr.status);
}abort 中止请求
var xhr = new XMLHttpRequest();
var timer = null;
xhr.onreadystatechange = function () {
if (xhr.readyState !== 4) return;
if (xhr.status >= 200 && xhr.status < 300 || xhr.status === 304) {
clearTimeout(timer); // 未超时则取消定时器
}
};
xhr.open("GET", "xxx");
xhr.send();
// 3秒后中止此次请求,请求超时
timer = setTimeout(function(){
xhr.abort();
}, 3000)get请求
- get请求
GET 请求一般用于信息获取,它没有请求主体,而是使用 URL 传递参数。对于 GET 请求,请求的结果会被浏览器缓存,特别是在 IE 浏览器下。这时,如果 GET 请求的 URL 不变,那么请求的结果就是浏览器的缓存(也就是上次 GET 请求的结果)。可以实时改变 GET 请求的 URL,只要 URL 不同,就不会取到浏览器的缓存结果。
get与post的对比
GET 请求:
- 一般用于信息获取:通过发送一个请求来取得服务器上的资源;
- 数据包含在 URL 地址中;
- 数据量受 URL 的长度限制;
- 不安全:浏览器的 URL 可见到,明文传输;
- GET 请求会被缓存;
- GET 没有请求主体,请求速度相对较快。
POST 请求:
- 一般用于修改服务器上的资源:向指定资源提交数据,后端处理请求后往往会导致服务器 建立新的资源 或 修改已有资源;
- 数据包含在请求主体中;
- 没有数据量限制,可在服务器的配置里进行限制;
- 只能是比 GET 安全,实际上也是不安全的:可通过开发者工具或者抓包看到,明文传输;
- POST 请求不会缓存;
- POST 相对稳定、可靠:可发送包含未知字符的内容。
fetch方法
fetch是原生方法。Fetch 提供了对 Request 和 Response (以及其他与网络请求有关的)对象的通用定义。
fetch与xhr不同的点
当接收到一个代表错误的 HTTP 状态码时,从 fetch() 返回的 Promise 不会被标记为 reject。即使该 HTTP 响应的状态码是 404 或 500。相反,它会将 Promise 状态标记为 resolve。仅当网络故障时或请求被阻止时,才会标记为 reject。
一个基本的 fetch 请求.
fetch('xxxxx')
.then(function(response) {
return response.json();
})
.then(function(myJson) {
console.log(myJson);
});fetch 接受第二个可选参数,一个可以控制不同配置的 init 对象:
postData('xxxxx', {answer: 42})
.then(data => console.log(data))
.catch(error => console.error(error))
function postData(url, data) {
//默认参数
return fetch(url, {
body: JSON.stringify(data), // must match 'Content-Type' header
cache: 'no-cache', // *default, no-cache, reload, force-cache, only-if-cached
credentials: 'same-origin', // include(包含凭证), same-origin,
headers: {
'user-agent': 'Mozilla/4.0 MDN Example',
'content-type': 'application/json'
},
method: 'POST', // *GET, POST, PUT, DELETE, etc.
mode: 'cors', // no-cors, cors, *same-origin
redirect: 'follow', // manual, *follow, error
referrer: 'no-referrer', // *client, no-referrer
})
.then(response => response.json()) // parses response to JSON
}cache
- default浏览器从HTTP缓存中寻找匹配的请求。
- 如果缓存匹配上并且有效, 它将直接从缓存中返回资源。
- 如果缓存匹配上但已经过期 ,浏览器将会使用传统的请求方式去访问远程服务器。如果服务器端显示资源没有改动,它将从缓存中返回资源。否则,如果服务器显示资源变动,那么重新从服务器下载资源更新缓存。
- 如果缓存没有匹配,浏览器将会以普通方式请求,并且更新已经下载的资源缓存。
- no-store — 浏览器直接从远程服务器获取资源,不查看缓存,并且不会使用下载的资源更新缓存。
- reload — 浏览器直接从远程服务器获取资源,不查看缓存,然后使用下载的资源更新缓存。
- no-cache — 浏览器在其HTTP缓存中寻找匹配的请求
- 如果有匹配,无论是新的还是陈旧的,浏览器都会向远程服务器发出条件请求。如果服务器指示资源没有更改,则将从缓存中返回该资源。否则,将从服务器下载资源并更新缓存。
- 如果没有匹配,浏览器将发出正常请求,并使用下载的资源更新缓存。
- force-cache — 浏览器在其HTTP缓存中寻找匹配的请求。
- 如果有匹配项,不管是新匹配项还是旧匹配项,都将从缓存中返回。
- 如果没有匹配,浏览器将发出正常请求,并使用下载的资源更新缓存。
- only-if-cached — 浏览器在其HTTP缓存中寻找匹配的请求。
- 如果有匹配项(新的或旧的),则从缓存中返回。
- 如果没有匹配,浏览器将返回一个错误。
credentials
- omit:从不发送凭证。
- same-origin:只有当URL与响应脚本同源才发送凭证。
- include:不论是不是跨域的请求,总是发送请求资源域在本地的凭证。
mode
- same-origin:同源,如果使用此模式向另外一个源发送请求,结果会是一个错误。
- no-cors:保证请求对应的 method 只有 HEAD,GET 或 POST 方法,并且请求的 headers 只能有简单请求头。
- cors:允许跨域请求,例如访问第三方供应商提供的各种 API。
- navigate:表示这是一个浏览器的页面切换请求(request)。navigate请求仅在浏览器切换页面时创建,该请求应该返回HTML。
fetch的优点
- 语法简洁,更加语义化
- 基于标准 Promise 实现,支持 async/await
- 同构方便,使用 isomorphic-fetch
- 更加底层,提供的API丰富(request, response)
- 脱离了XHR,是ES规范里新的实现方式
- 跨域的处理
我们都知道因为同源策略的问题,浏览器的请求是可能随便跨域的——一定要有跨域头或者借助JSONP,但是,fetch中可以设置mode为"no-cors"(不跨域),如下所示:
fetch('xxxx', {
method: 'post',
mode: 'no-cors',
data: {}
}).then(function() { /* handle response */ });这样之后我们会得到一个type为“opaque”的返回。需要指出的是,这个请求是真正抵达过后台的,所以我们可以使用这种方法来进行信息上报。让后端来控制跨域。
fetch的abort
fetch除了400,500请求会返回成功外,还有一个比较大的缺点是无法像XHR一样直接调用abort取消请求。但是可以通过AbortController来实现。
AbortController 的基本用法
// 创建 AbortController 的实例
const controller = new AbortController()
const signal = controller.signal
// 监听 abort 事件,在 controller.abort() 执行后执行回调打印
signal.addEventListener('abort', () => {
console.log(signal.aborted) // true
})
// 触发中断
controller.abort()如何使用 AbortController 中断 fetch 请求?
const controller = new AbortController()
const signal = controller.signal
fetch('xxx', { signal }).then(r => r.json())
.then(response => console.log(response))
.catch(err => {
if (err.name === 'AbortError') {
console.log('Fetch was aborted')
} else {
console.log('Error', err)
}
})
setTimeout(() => controller.abort(), 2000)上面就可以实现一个可以中断的 fetch 请求。